
快手探索者 LLM-Rec 挑战赛 · 万擎平台介绍
💡 如需查看平台相关问题解答,可直接前往本文第五部分 FAQ 板块
一、平台简介
快手万擎是企业级模型服务与 AI 算力云平台,集成高性能模型推理、低成本模型定制与托管服务。万擎平台作为本次赛事官方技术平台,为参赛选手提供数据管理、模型精调与评测等能力支持。
二、能力速览
📌 提示:本文档所述平台能力及竞赛专属资源将于赛事正式开始后开放,具体时间以比赛官网为准。
万擎平台为本次比赛开放以下四项核心能力,覆盖从数据准备、模型训练、模型管理到竞赛评测的完整参赛链路:
2.1 数据集
"训练数据从哪来、怎么统一管理?"
- 上传数据:支持上传 JSONL、CSV、XLSX 等常见格式,平台自动校验数据格式,无需手动排查
- 多版本管理:同一数据集可多版本迭代,方便对比不同数据配比下的训练效果
- 数据集选用:内置竞赛专项数据集,精调时可直接调用
2.2 模型训练
"如何高效完成模型训练与多轮迭代?"
平台提供两种训练方式,推荐优先使用模型定制-精调,精调训练任务由平台全托管调度,完成后模型可自动归档并直连竞赛评测入口,无需手动导出与上传,显著缩短单轮迭代周期。有自定义训练脚本需求的选手,可选择模型研发-开发机。
2.2.1 模型定制-精调(推荐)
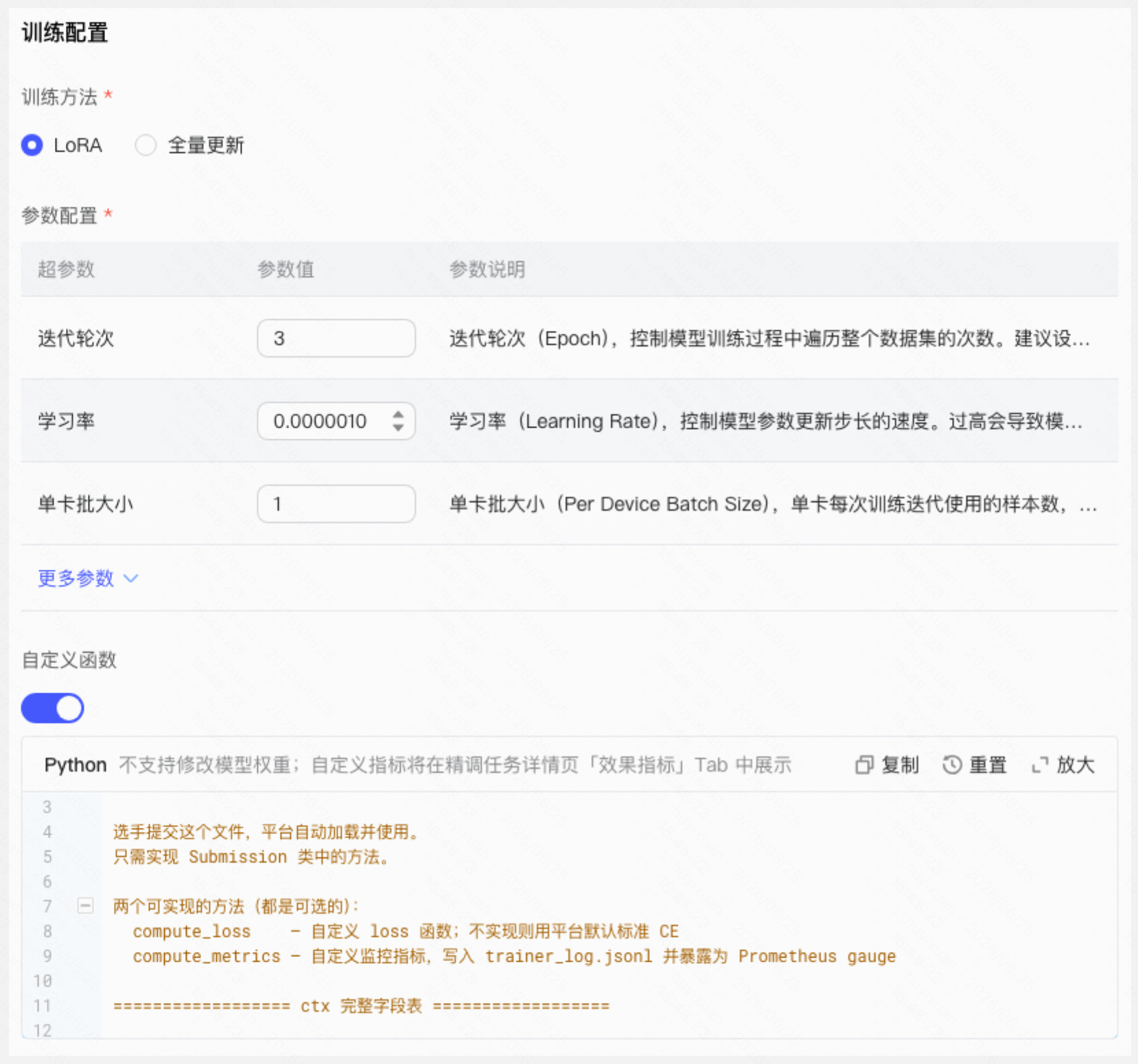
- 训练方法:提供 LoRA 和全量更新两种选择——LoRA 训练快、消耗低,适合快速验证方向;全量更新调优上限更高,适合精细打磨
- 超参数配置:灵活配置迭代轮次、学习率、批大小等,新手可直接使用平台默认值
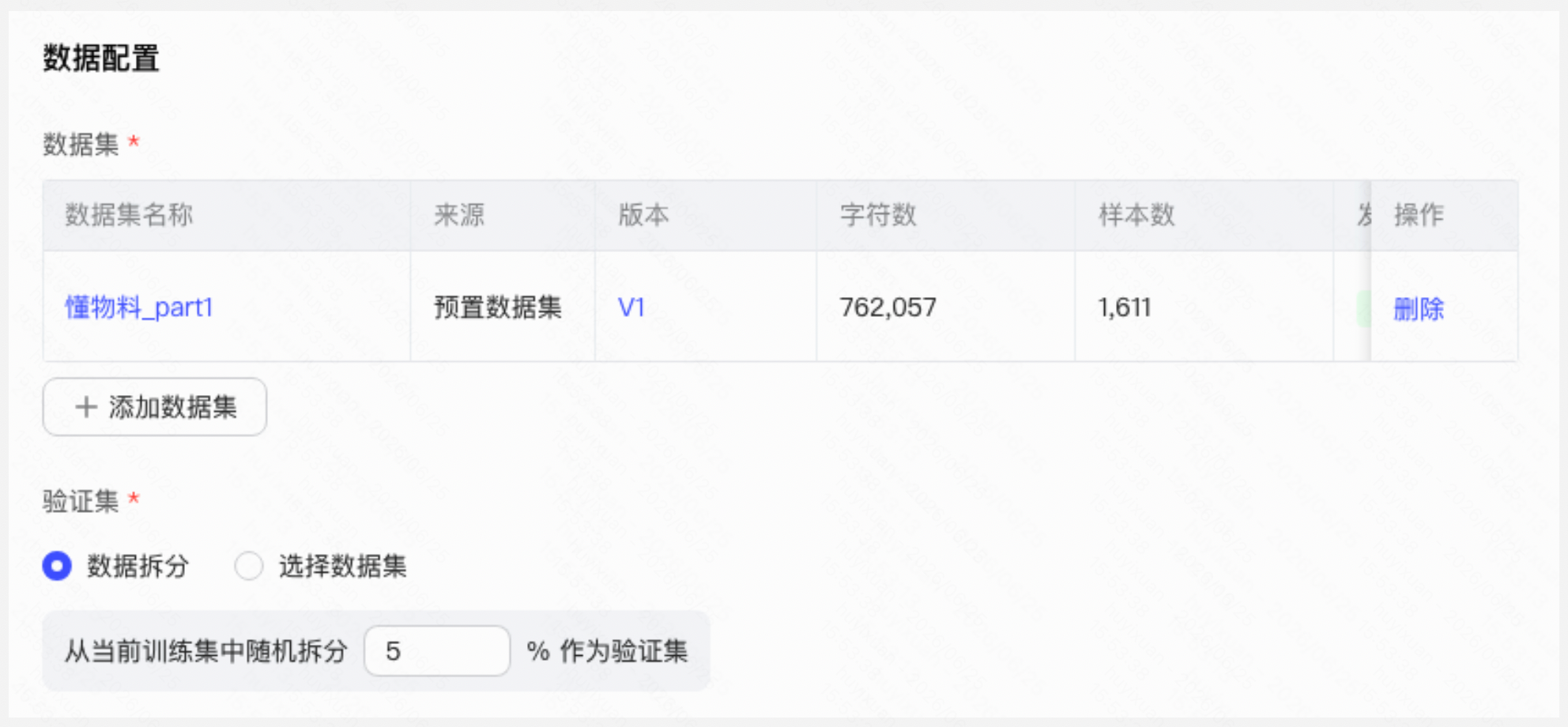
- 数据配置:支持多数据集混合训练,可从训练集随机拆分验证集或单独指定,灵活适配不同数据准备情况
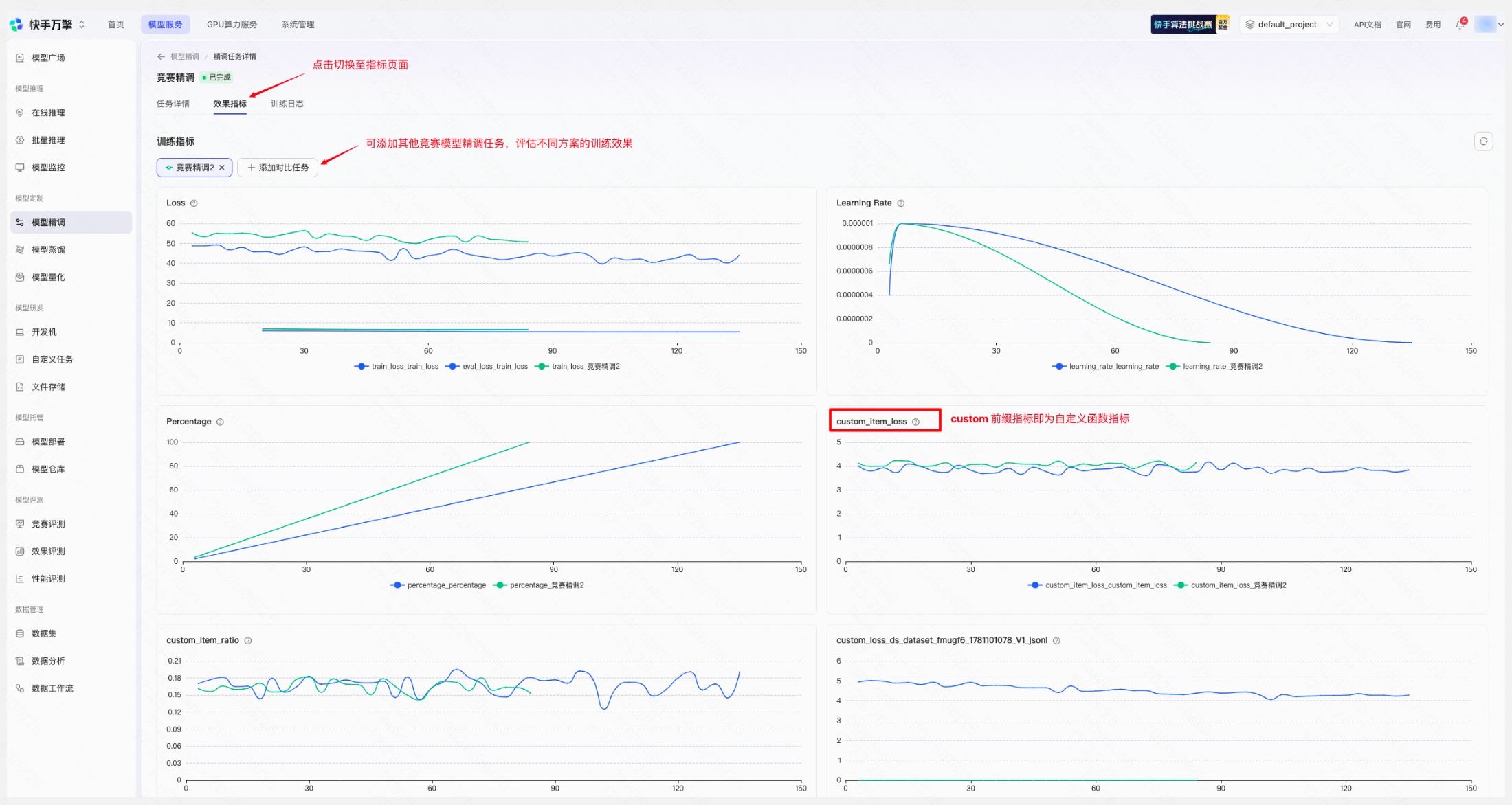
- 过程可视化:预置 train_loss、eval_loss 等常用指标曲线,支持自定义监控指标,多任务曲线可叠加对比
2.2.2 模型研发-开发机
- 在线编码调试:提供云端 VS Code 和 Terminal,无需本地搭建环境
- 预置开发镜像:预置 PyTorch、ms-swift 等常用框架镜像,开机即可训练
- 持久化存储:支持挂载共享存储,数据和模型文件不丢失
2.3 模型仓库
"训练产出如何归档与追踪?"
- 自动归档:精调产出模型可自动归档至仓库,无需手动导出
- 手动上传:开发机训练完成后,从本地上传模型文件即可提交评测
2.4 竞赛评测
"模型训练效果怎么量化?"
- 正式评测:一键提交,平台自动调用 OneRec Benchmark 评测集打分,无需自行部署模型或编写评测脚本
- 查看结果:评测完成后可查看「懂物料、懂用户、懂推荐、懂世界」四维度得分,快速定位能力短板,指导下一轮精调方向
⚠️ 注意:正式评测每日限提交 3 次,请合理规划提交时机。
三、登录指南
📌 本次比赛请认定万擎平台唯一站点:https://www.streamlake.com/product/wanqing
3.1 实名认证
- 使用队长赛事报名时注册的账号登录万擎官网,将鼠标移至右上角用户头像,进入「账号中心」点击「实名认证」。选择「个人实名认证」并提交认证信息:
- 个人实名支持扫脸认证,可即时通过
- 个人身份证认证需审核1-3个工作日,请耐心等待
- 认证完成后,进入「控制台」即可开通快手万擎业务。
3.2 团队账号使用
平台支持同一账号多终端同时登录,推荐团队共用队长注册账号,参赛资源也将统一发放至队长账号中。
四、模型训练与竞赛评测实操流程
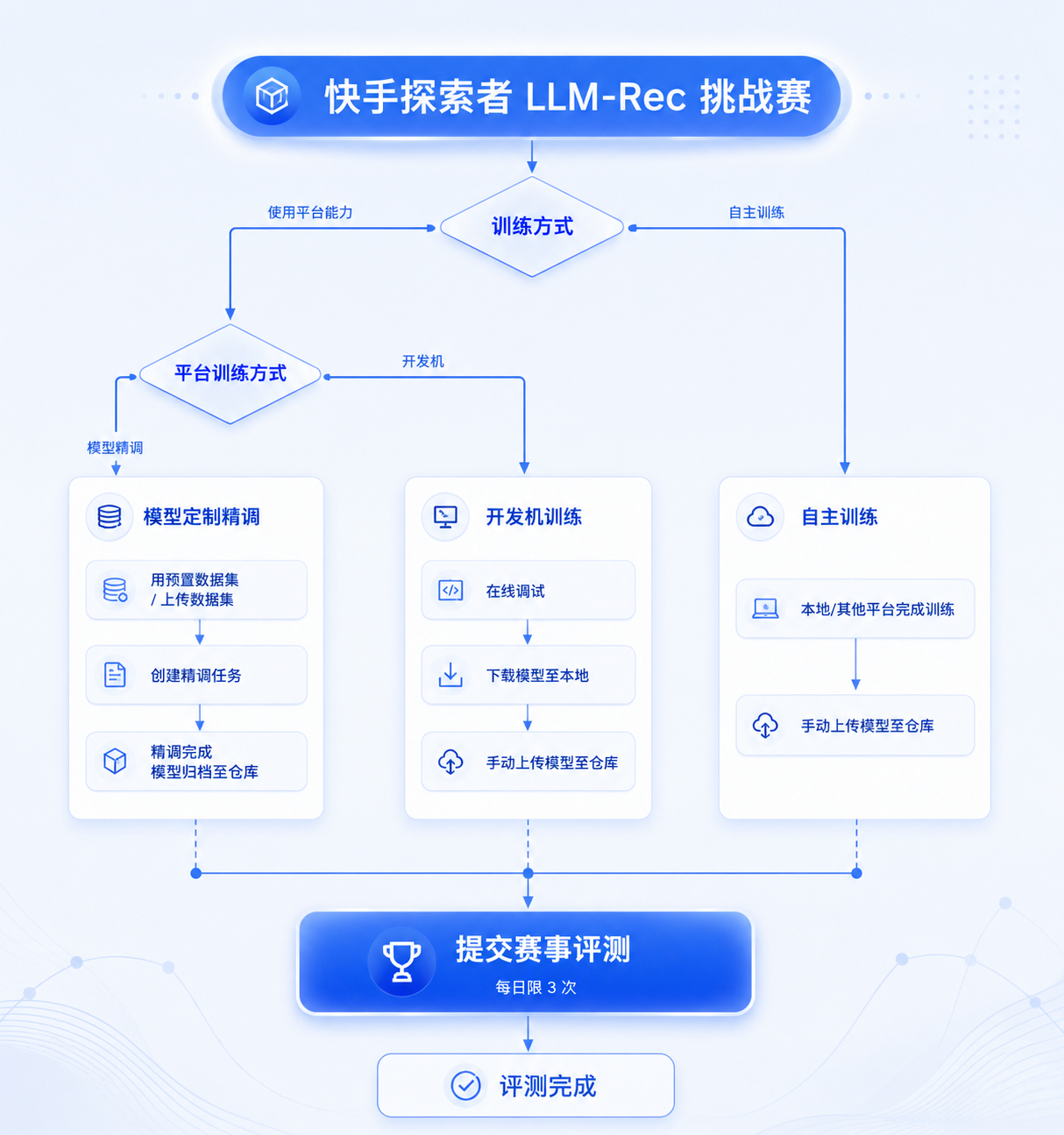
本次比赛支持三种参赛路径,选手可根据自身情况选择:
- 如果希望快速跑通完整参赛流程、把精力放在数据和调参上,可使用模型定制-精调,平台托管训练全流程,完成后一键直连评测
- 如果有自定义训练代码(如特殊的 loss 函数、数据处理逻辑),需要更灵活的开发环境,推荐使用模型研发-开发机,训练完成后手动上传至仓库再提交评测
- 如果已在本地或其他平台完成训练,可直接将模型文件上传至仓库参与评测
4.1 路径一:使用平台能力训练模型
4.1.1 模型精调训练
本教程将引导选手完整走一遍参赛核心流程:上传数据集 → 创建精调任务 → 提交竞赛评测,快速完成首次上手。
4.1.1.1 上传数据集
平台已为本次竞赛预置官方专项数据集,精调时可直接调用。如果选手希望在官方数据基础上进一步优化模型效果,也可上传自有训练数据进行混合训练:
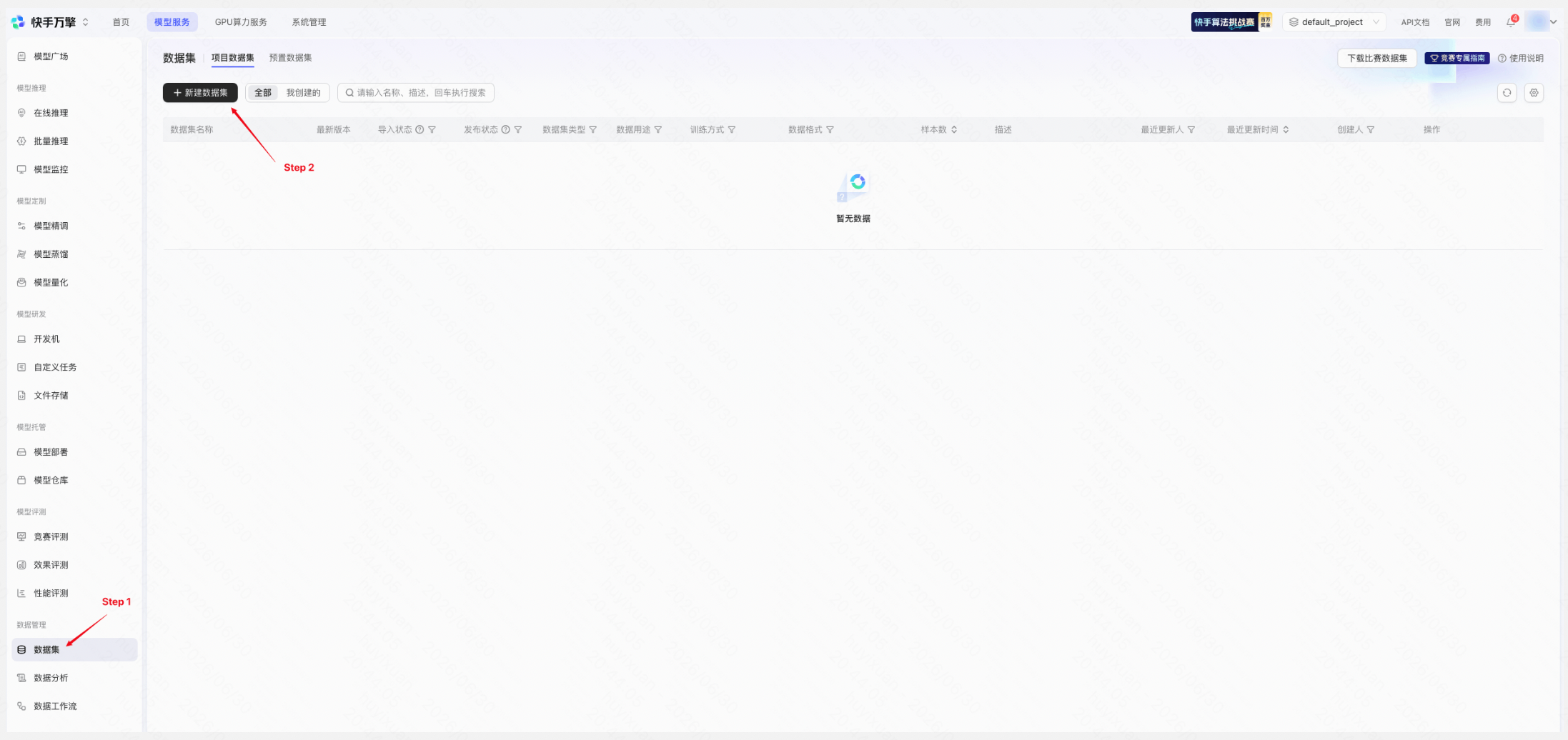
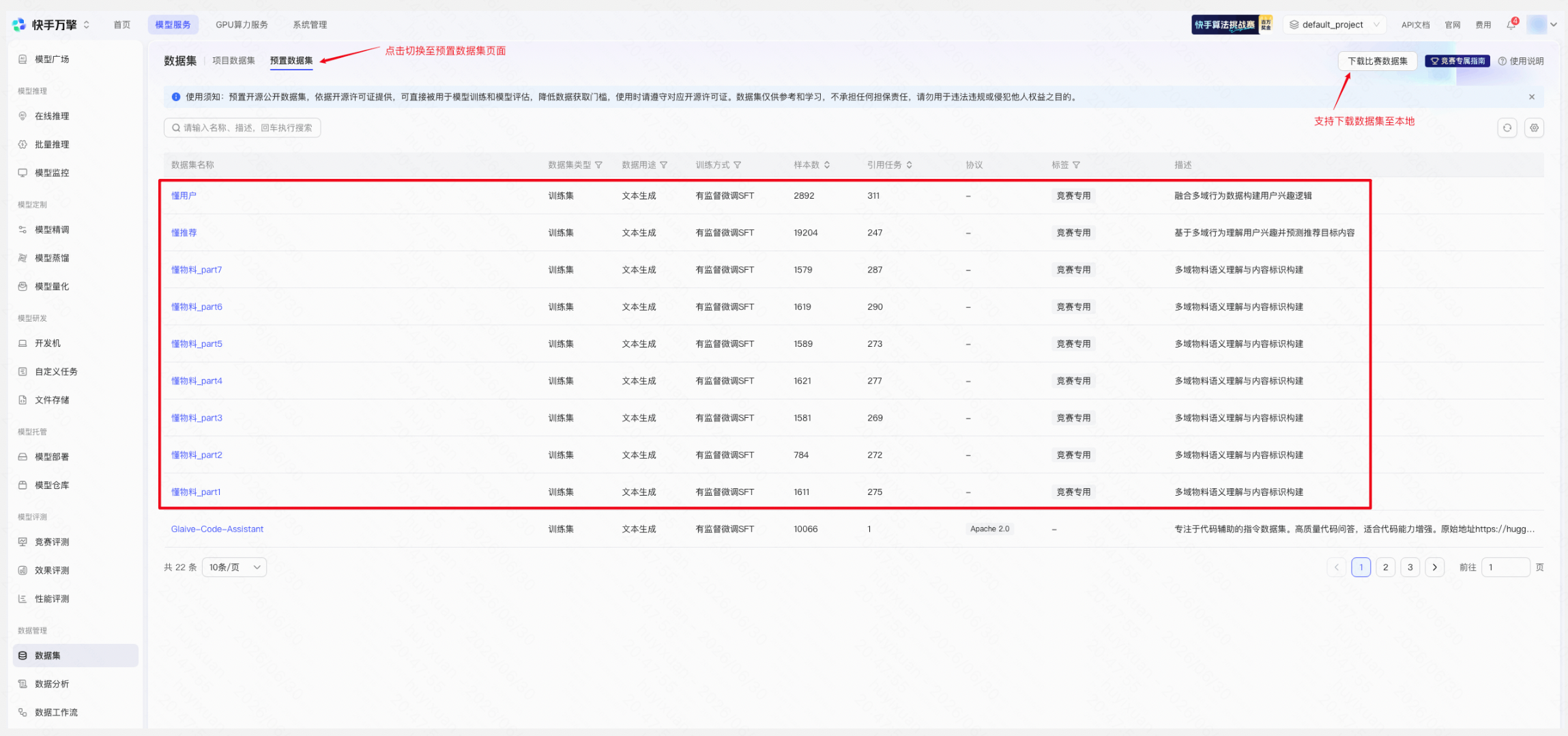
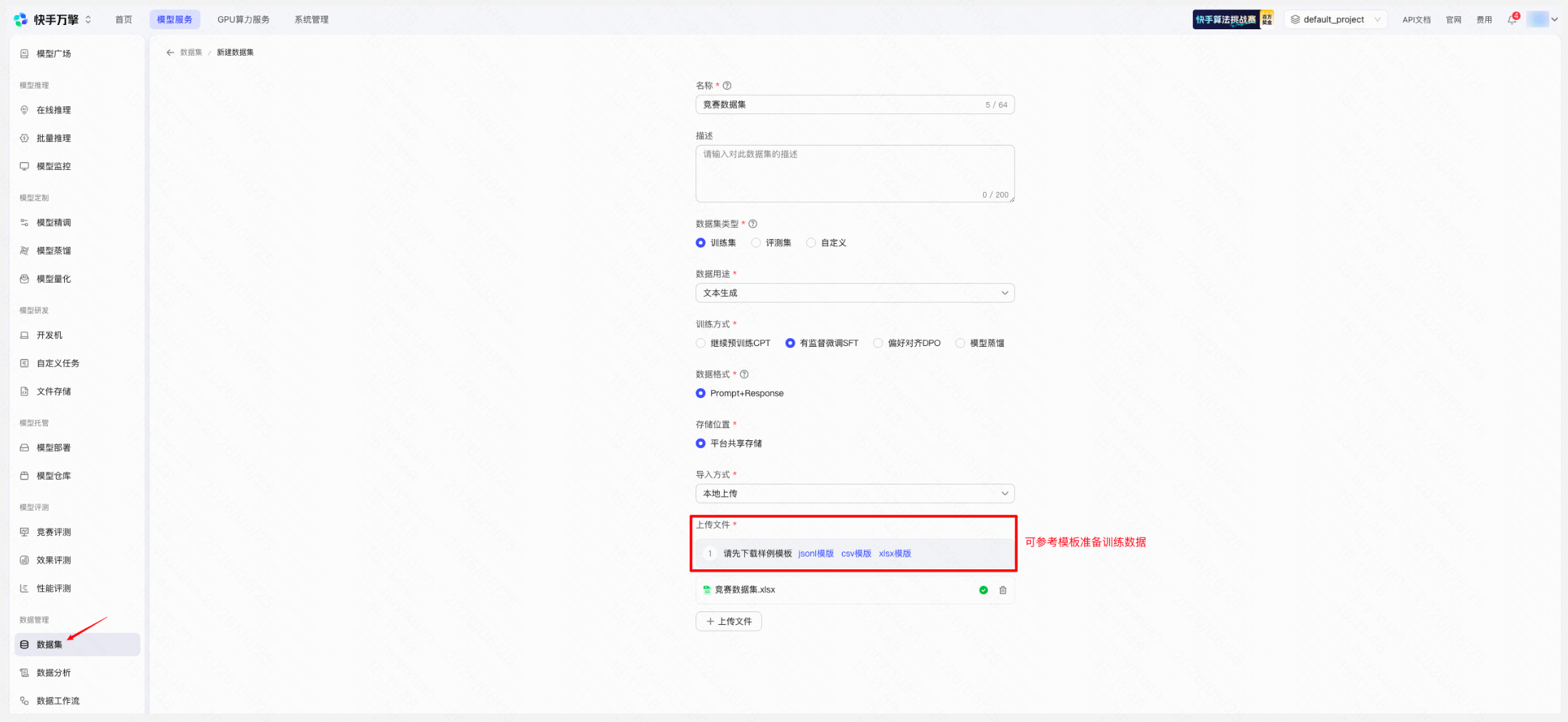
操作路径: 左侧导航栏「数据管理」→「数据集」→ 点击「+ 新建数据集」
创建数据集 | 平台页面示例 |
填写信息
|
4.1.1.2 创建精调任务
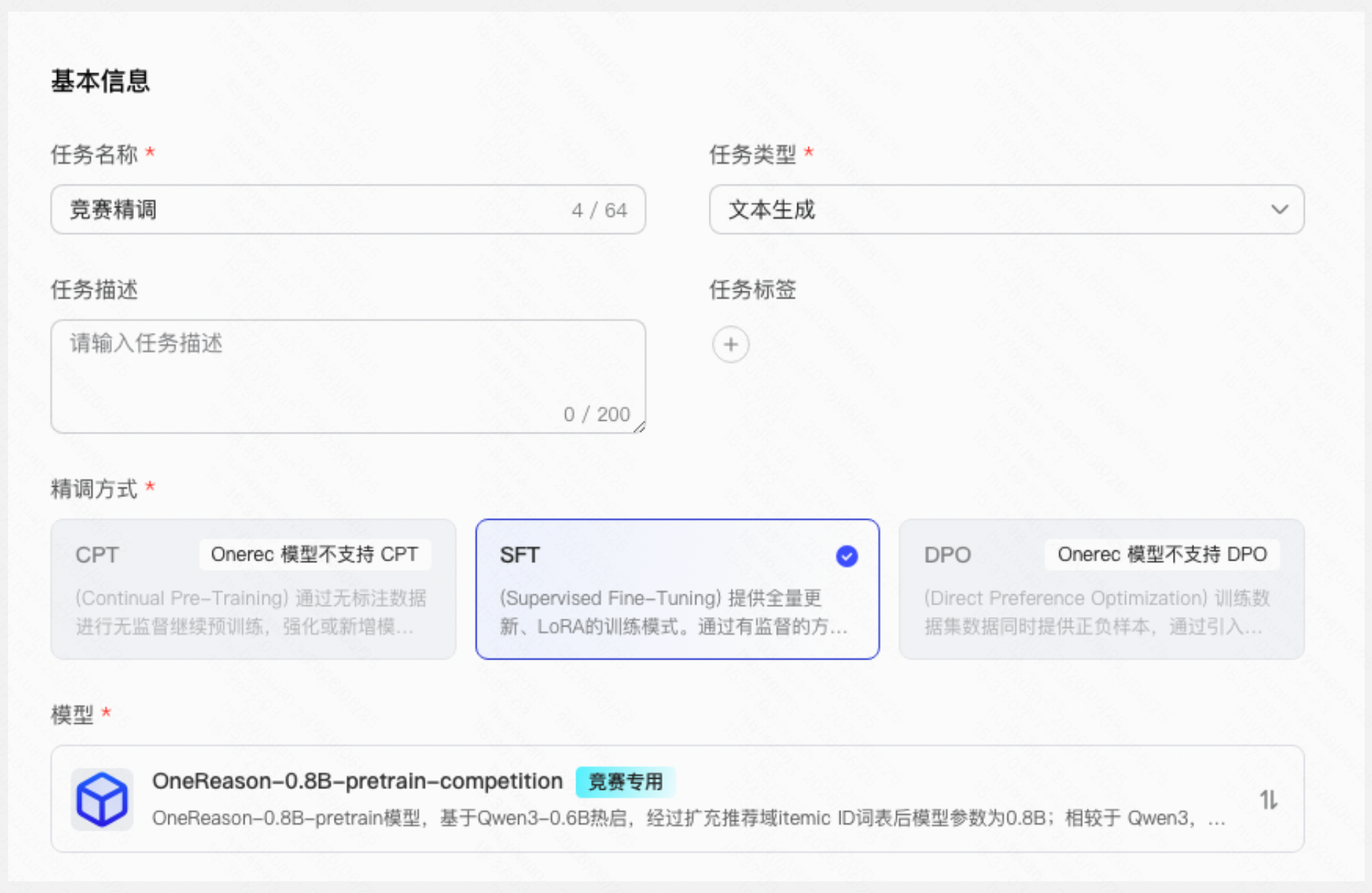
精调任务是本次竞赛的核心训练环节,平台为本次赛事提供了 OneReason-0.8B-pretrain-competition 竞赛专用模型,选手需基于该模型进行精调训练。
操作路径: 左侧导航栏「模型定制」→「模型精调」→ 点击「+ 新建精调任务」
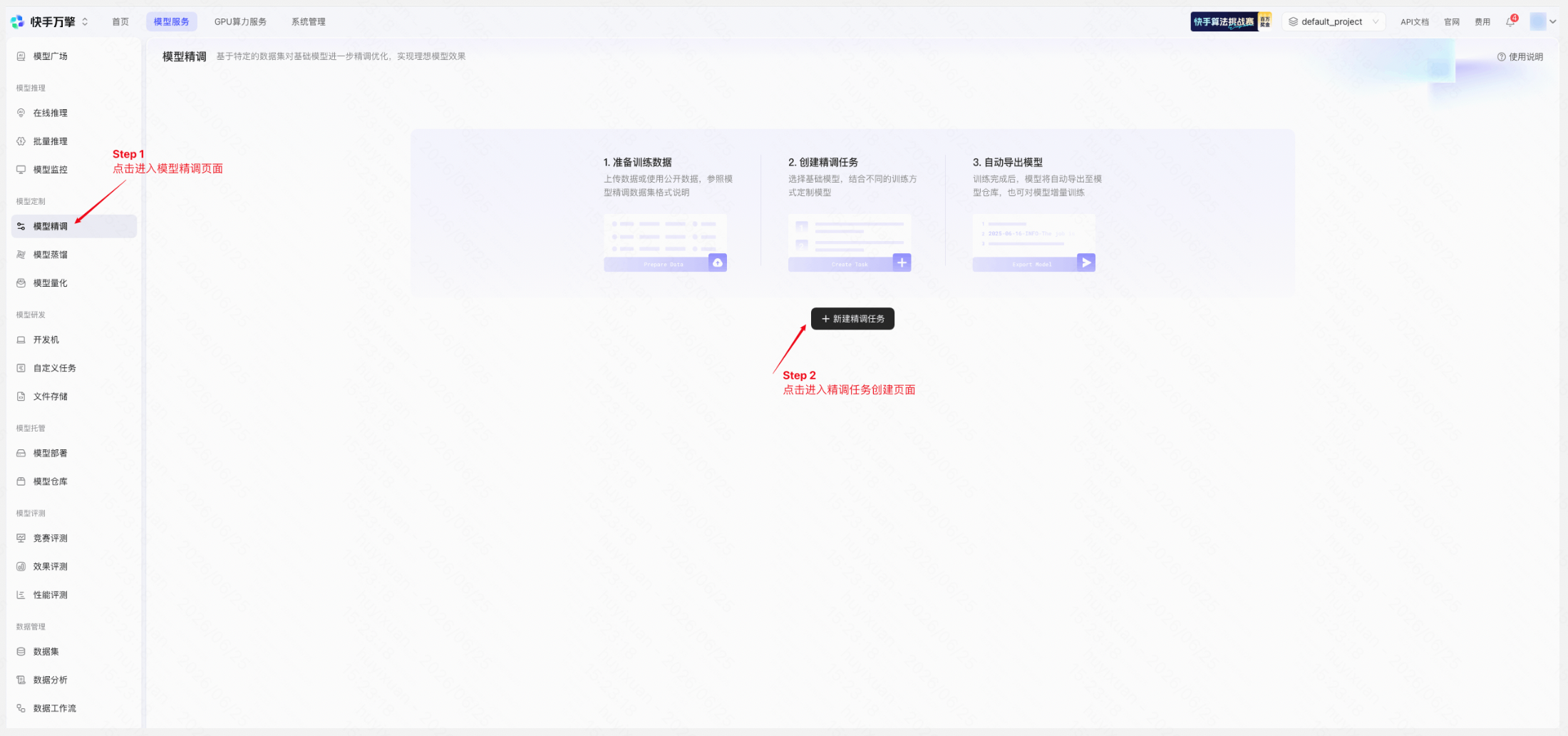
创建精调任务 | 平台页面示例 |
基本信息
| |
训练配置
| |
数据配置
| |
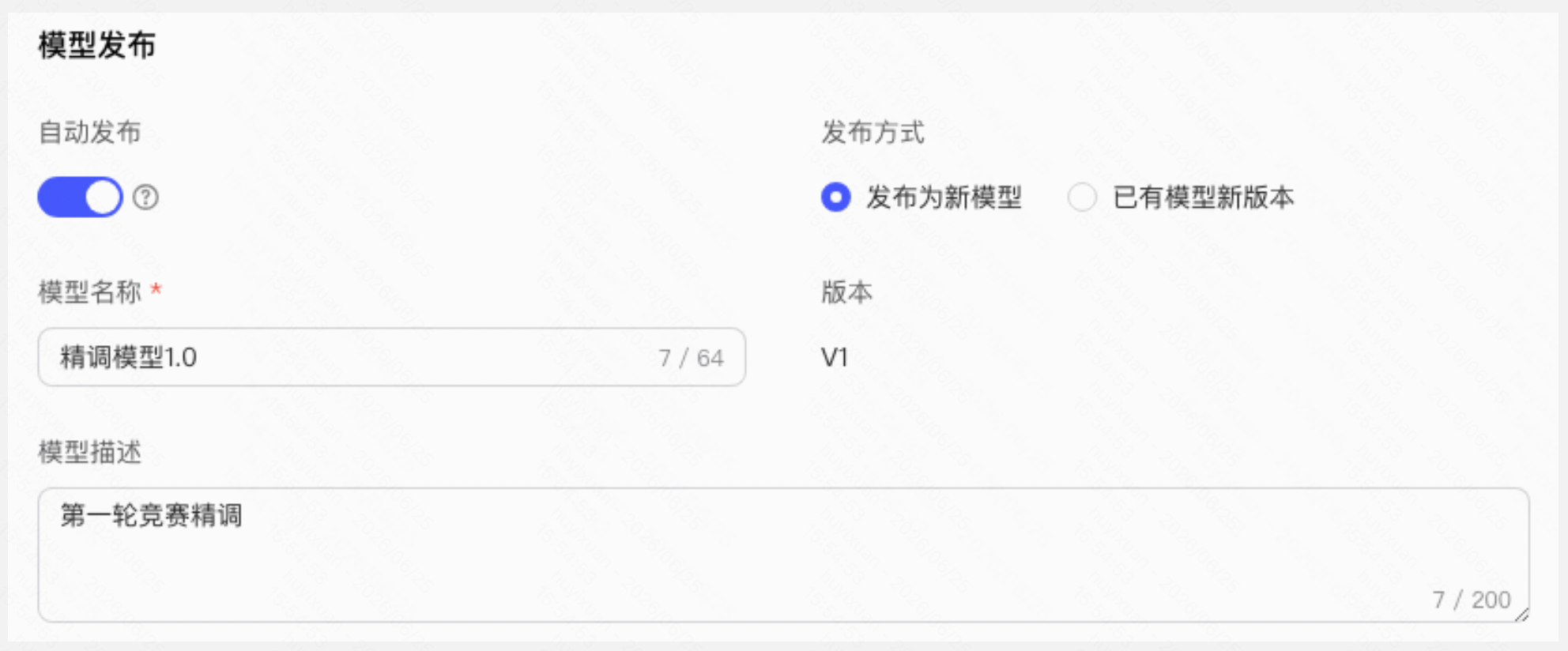
模型发布 训练完成后,模型需要发布到「模型仓库」才能提交竞赛评测。
|
完成提交:所有配置填写完毕后点击「提交」,任务将进入排队等待资源调度,排队时间取决于当前竞赛期间的任务量。
🔔 代金券/折扣券使用提示:卡券会在任务成功后触发扣减,任务处理有耗时,建议选手在优惠券有效期前24h提交任务。
查看精调任务
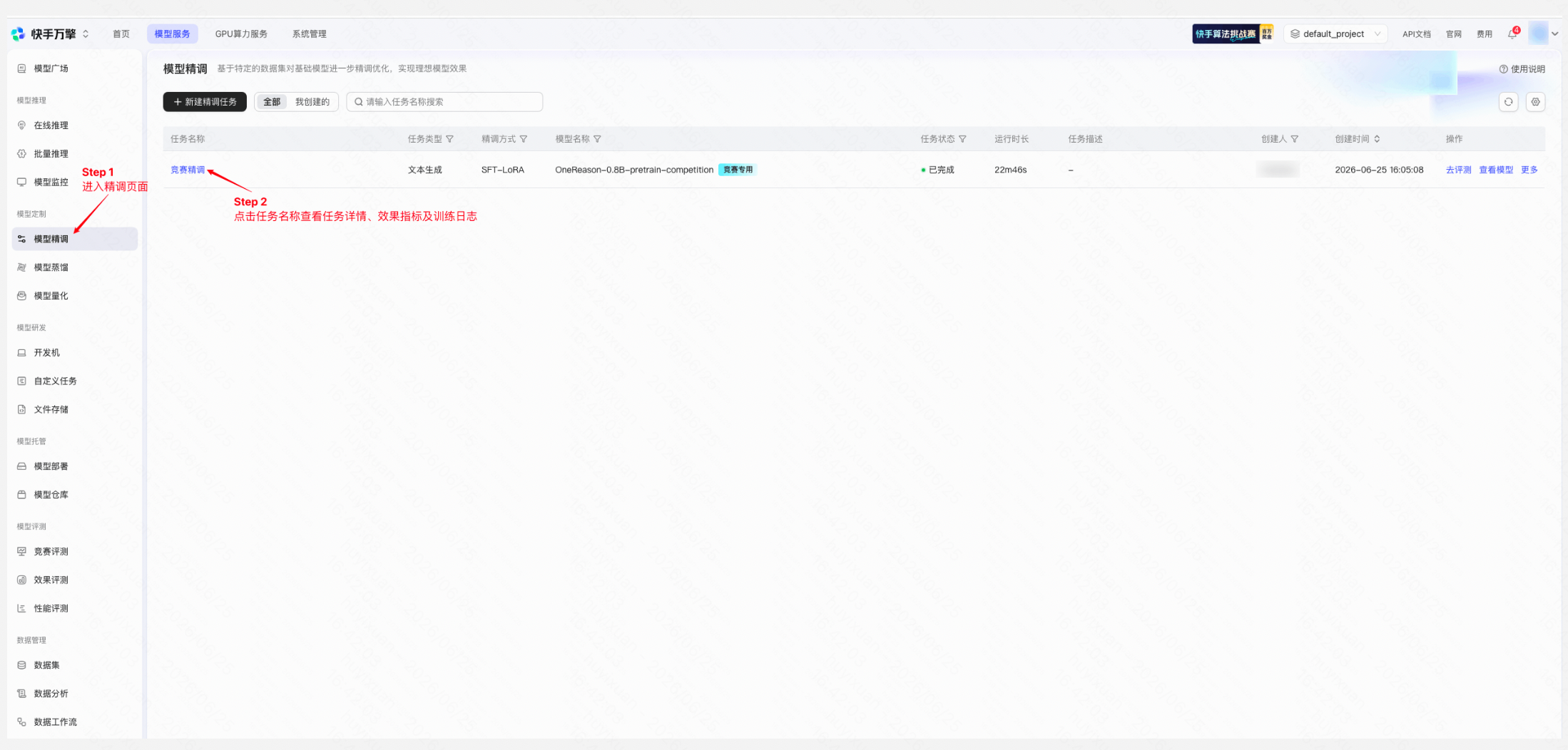
操作路径: 左侧导航栏「模型定制」→「模型精调」
任务列表页展示当前项目下所有精调任务,包含任务名称、任务类型、精调方式、模型名称、任务状态、运行时长等信息,点击任务名称即可查看任务详情:
查看精调任务 | 平台页面示例 |
任务详情
| |
效果指标
| |
训练日志
|
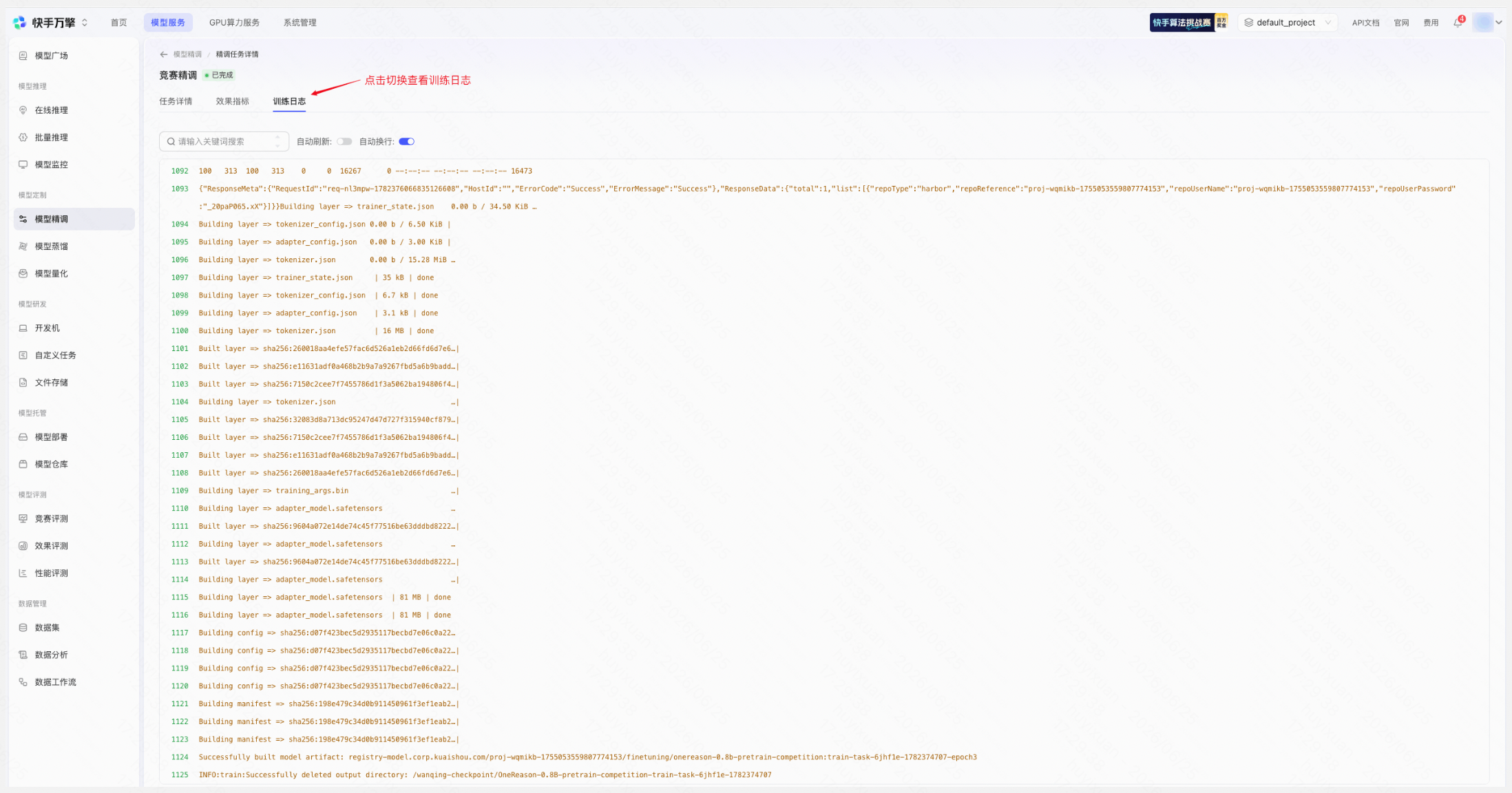
4.1.1.3 提交竞赛评测
精调任务完成、模型已发布至仓库后,即可提交竞赛评测。评测完成后平台将自动计算各维度得分,无需选手自行部署模型或编写评测脚本。
创建入口一: 精调详情页右上角点击「去评测」,自动跳转并回填模型信息
创建入口二: 左侧导航栏「模型评测」→「竞赛评测」→ 点击「+ 新建评测任务」
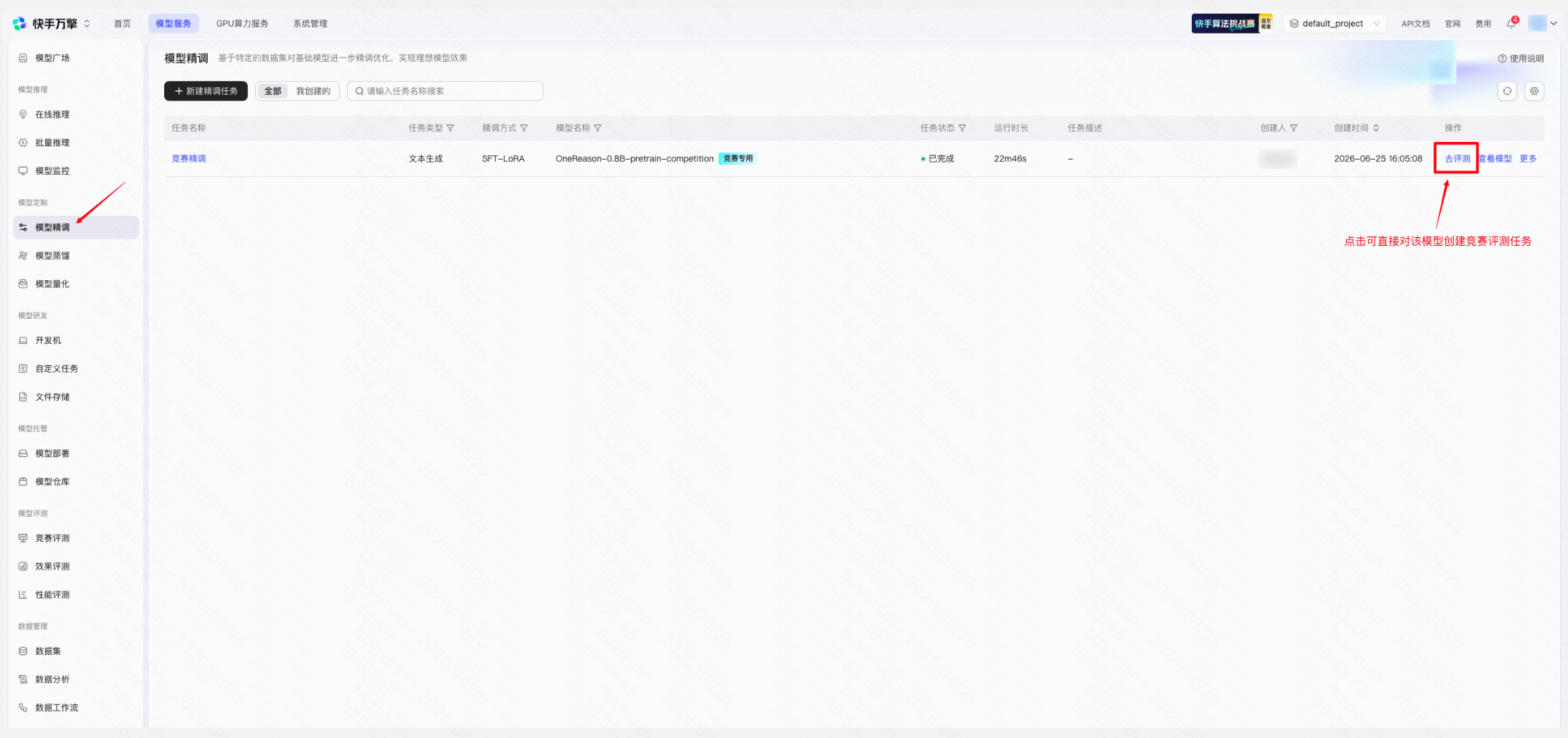
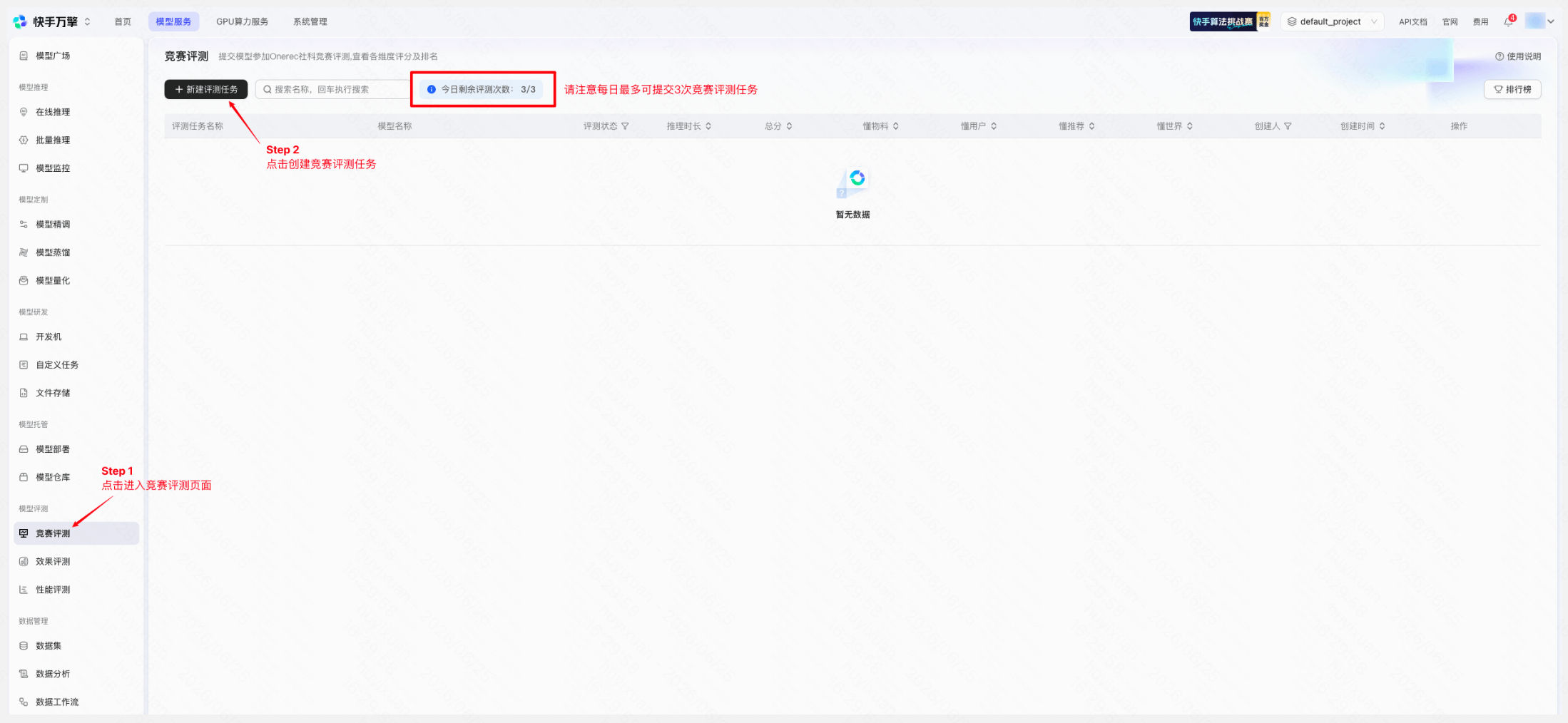
新建竞赛评测任务 | 平台页面示例 |
|
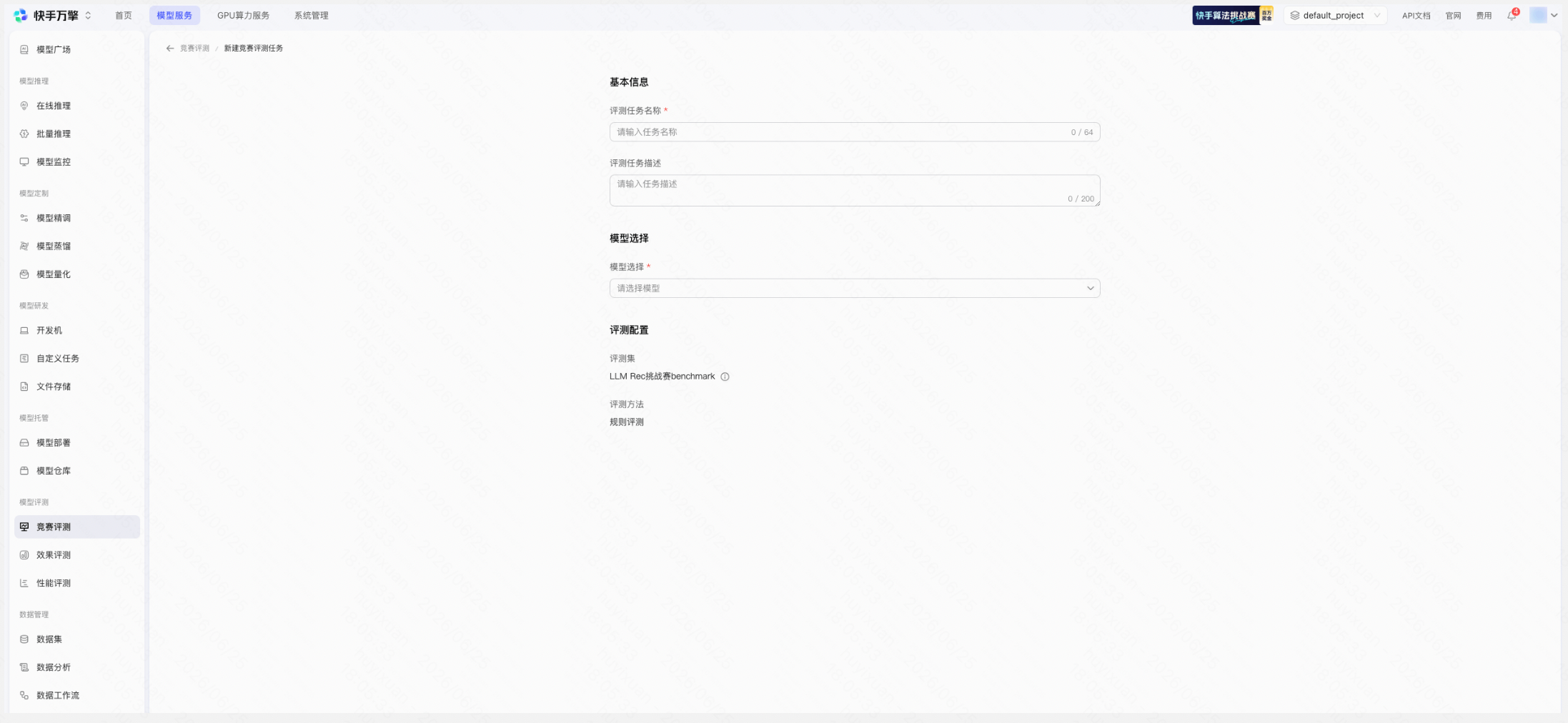
查看评测结果
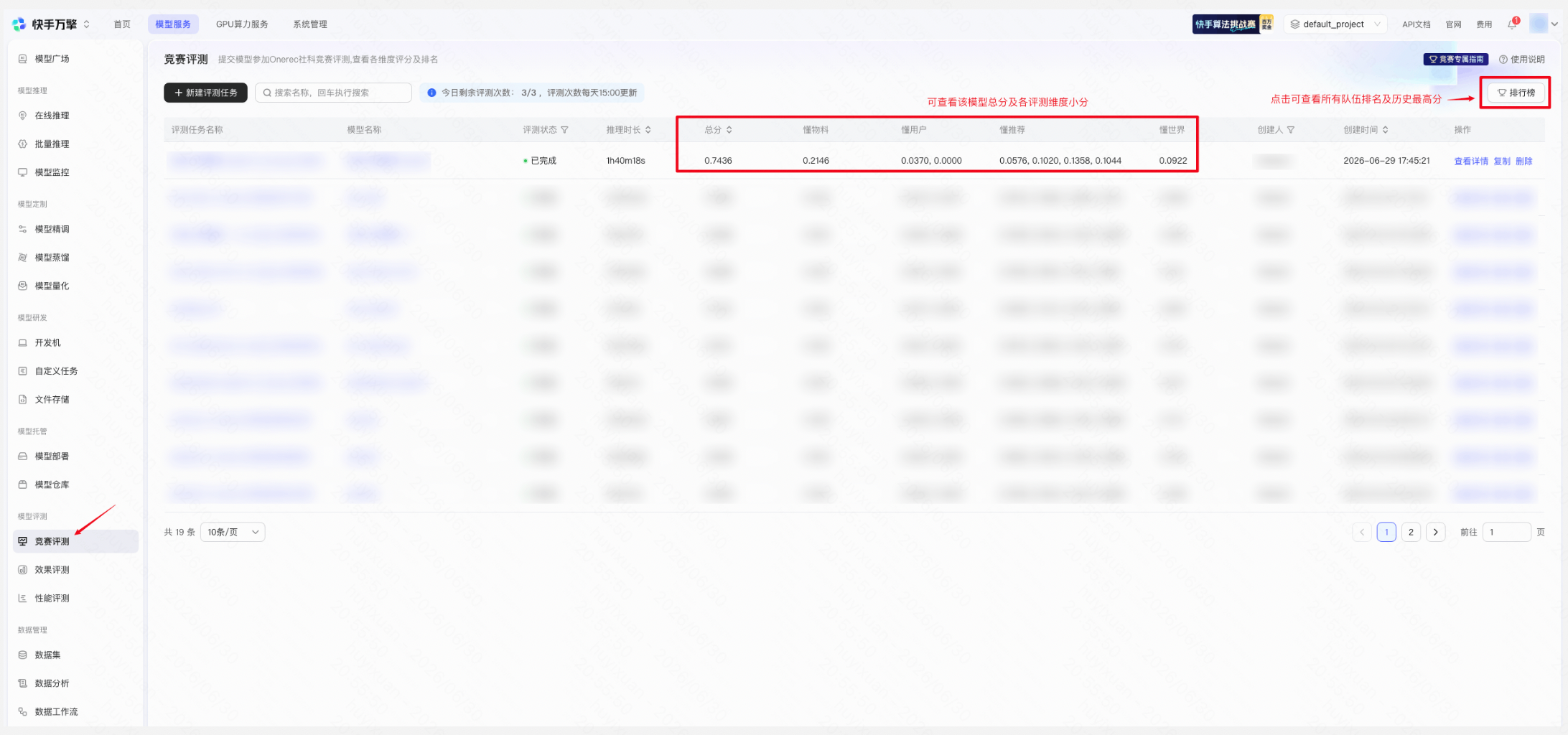
操作路径: 左侧导航栏「模型评测」→「竞赛评测」
评测任务列表展示所有评测记录,包含评测任务名称、模型名称、评测状态、推理时长及各维度得分:
查看竞赛评测任务 | 平台页面示例 |
|
4.1.2 开发机训练
开发机完整使用教程详见:开发机使用文档 | 竞赛模型 HuggingFace 链接
训练完成后,将模型文件下载至本地,再参考下方 4.2 自主训练模型 提交竞赛评测。
4.2 路径二:自主训练模型
针对未使用万擎精调能力的选手,可将训练好的模型上传至平台后进行竞赛评测,本教程将引导选手完整走一遍参赛核心流程:上传模型 → 提交竞赛评测,快速完成首次上手。
4.2.1 上传模型
操作路径: 左侧导航栏「模型仓库」→ 点击「上传模型」
上传模型 | 平台页面示例 |
|
4.2.2 提交竞赛评测
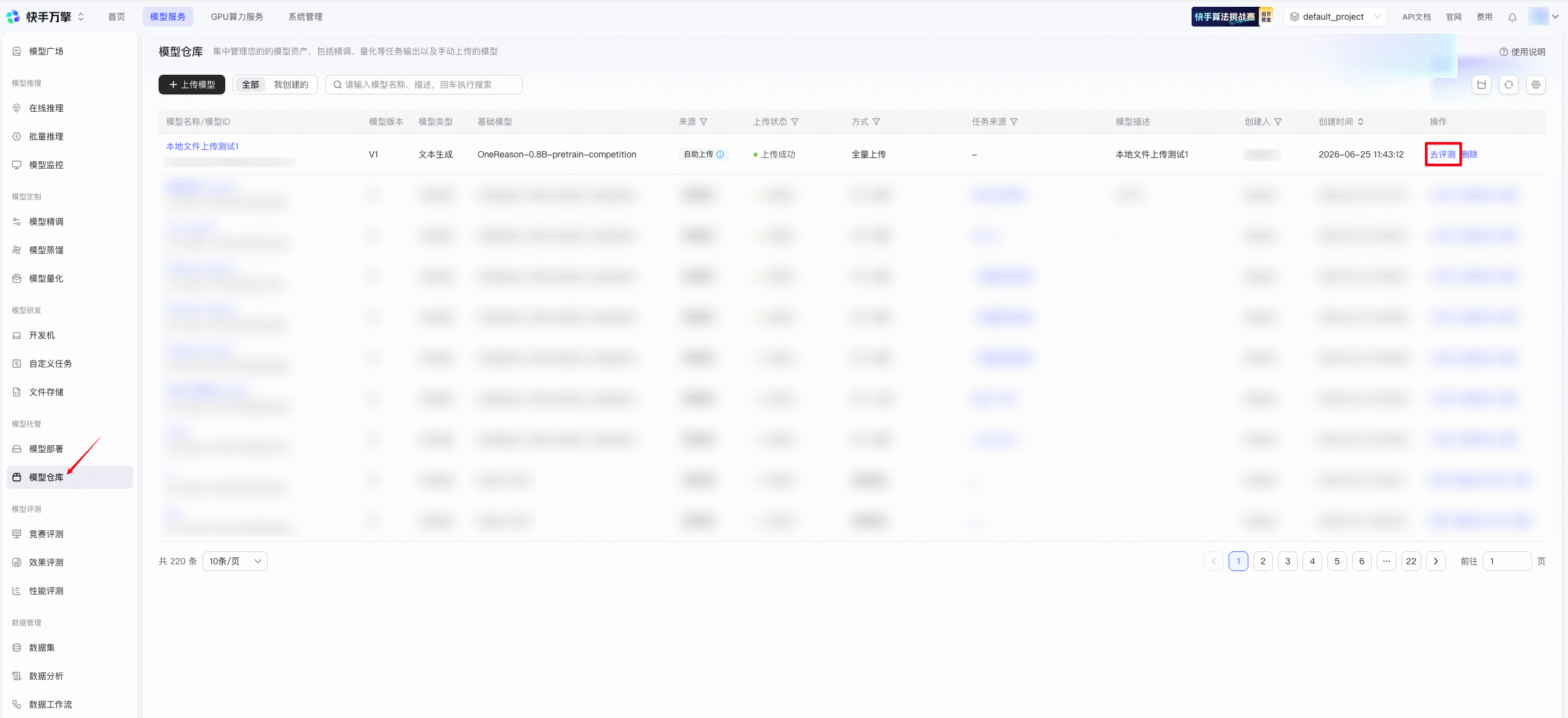
当模型成功上传至仓库后,即可提交竞赛评测。评测完成后平台将自动计算各维度得分,无需选手自行部署模型或编写评测脚本。
操作路径: 左侧导航栏「模型仓库」→ 选择上传的模型,点击「去评测」
新建竞赛评测任务 | 平台页面示例 |
|
查看评测结果
操作路径: 左侧导航栏「模型评测」→「竞赛评测」
评测任务列表展示所有评测记录:
查看竞赛评测任务 | 平台页面示例 |
|
五、FAQ
数据准备与使用
Q1:关于数据集的整体说明
A:我们提供了两类数据,一类是 种子SFT 数据(该部分LLamaFactory框架直接可用,可在万擎平台下载),另一类是原始的用户行为序列以及物料元信息、以及通识数据(需选手自行处理,通过Huggingface下载)。
其中种子SFT数据分为懂物料/懂用户/懂推荐三块,该批数据从原始的用户行为序列清洗得到,此处仅作为参考,了解OneReason的SFT数据格式,选手也可以自行进行额外清洗、配比等操作;
对于原始数据,包含大量用户在短视频、电商、直播、广告四个领域的交互行为,每个行为序列的物品id经过哈希,可以通过pid2sid 表找到对应的sid,也可通过pid关联可能存在的caption和tag。详细介绍可以参考 数据解释。选手可基于转化后的sid行为序列构造SFT数据,转换为LLamaFactory可用的数据格式,进行增量数据配比训练模型。
Q2:可以把数据集下载到自己的电脑上,用自己的电脑训练吗?
A:选手能够从HugginFace上下载模型预训练参数,同时结合平台上下载的赛事专用数据集,开始模型训练。赛事过程中,万擎平台每周会提供限量训练资源(3B+),同时选手也可自备算力进行训练。
Q3:比赛是只能在官方数据集上做处理,还是可以引入外部数据集进行调优?
A:数据集方面,选手有高度的灵活性,包括但不限于:引入外部通识数据、构造定制化推荐数据等;但在复现阶段,需要选手提供对应构造好的数据集,以及对应的训练脚本,官方进行模型效果续训复现,模型评估效果在误差内即可。
Q4:有数据集 Demo 和 Baseline 吗?
A:开赛后,万擎官网 SFT 数据集下载方式为:【模型服务】-【数据管理】-【数据集】-【下载比赛数据集】;用户原始行为序列&本地微调baseline下载请点击:下载地址
Q5:预置数据集只能用竞赛专用的吗?其他的可以用吗?
A:其他预置数据集为万擎提供的通用数据,如果需要可以自由选用。
模型训练
Q1: 初赛只能在平台上自动训练,是否不需要写代码了?
A:我们会提供 baseline 模型和 baseline 训练代码,有以下两种方式迭代模型:1. 选手可以基于自备资源或使用万擎平台-开发机来进行模型训练,这样训练框架可自行修改;2. 选手基于万擎平台-模型精调功能进行训练,此时baseline模型框架无法修改,但可修改主要训练参数,与自定义loss监控功能。
Q2:只能使用0.8b的onereason模型作为预训练模型吗?
A:初赛阶段,我们只允许选手基于OneReason-0.8B进行迭代,在评测时,会严格校验模型对应的config参数是否与baseline模型一致。
Q3: Baseline会提供RL的代码吗?
A:Baseline不会提供RL的训练代码,需要选手自行实现。
Q4:比赛有什么限定吗?是提供一个pretrain model 然后大家在上面ft吗?
A:选手可以结合pretrain model以及赛事数据集,自行进行SFT数据配比、搭建RL pipeline来训练模型。在赛事过程中,选手无法修改模型结构、模型预定义参数、以及评估参数设置,需在统一环境下评测模型效果。
Q5:精调训练的序列长度为什么不能调整?
A:序列长度和批大小,我们已经帮您选取了最佳的参数值,您不需要调整此参数。
Q6:比赛限制蒸馏吗,限制多模融合吗?
A:允许使用模型蒸馏;在赛事过程中,我们全程不鼓励使用模型融合进行提分,选手需要在复赛结束时提供单模型训练方案进行代码审核以及复现。
Q7:从哪里可以看到baseline的性能指标?
A:pre-train模型的分数,大约在0.67左右,分数波动范围大约在1个百分位左右(这是由于目前使用的vllm框架推理,该波动无法避免)。
以下评估结果仅供参考:
总分:0.6655
懂物料:0.1533
懂用户:0.0000, 0.0055
懂推荐:0.0864, 0.0544, 0.1372, 0.0900
懂世界:0.1387
竞赛评测
Q1:比赛需要上传模型权重吗?
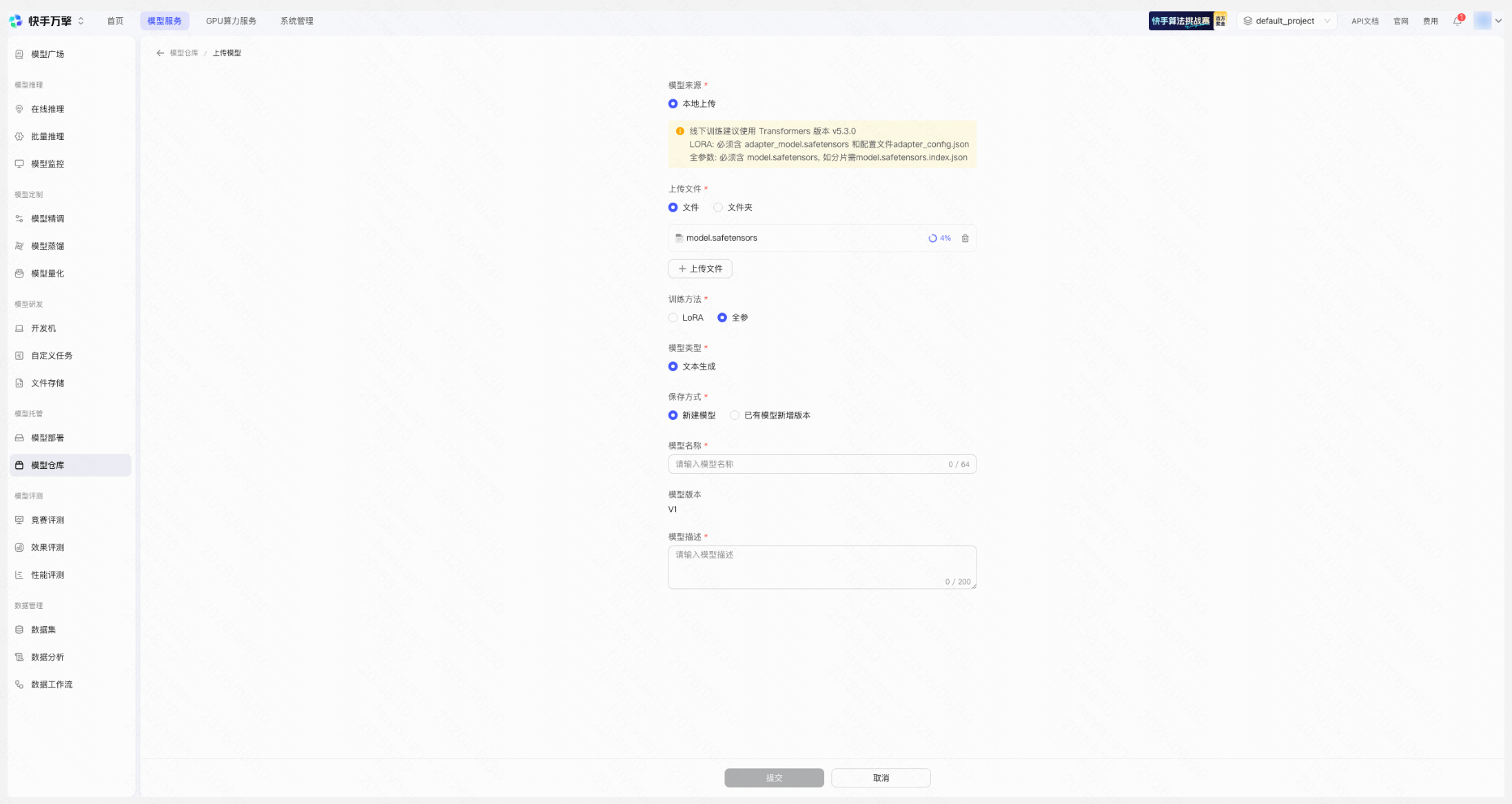
A:本次竞赛支持通过平台精调训练、开发机及线下训练,如果使用万擎模型精调服务,则无需上传CKPT;如果选手使用自备资源、或者开发机训练模型,则需要每次上传CKPT:
- lora 需要上传模型文件 adapter_model.safetensors 和配置文件 adapter_config.json
- 全量模型需要上传 model.safetensors, 如果分片,还需要 model.safetensors.index.json
线下训练建议使用 Transformers 版本 v5.3.0
Q2:各个子任务的得分是原始指标还是乘过权重后的得分?总分是怎么算的?
A:由于各任务之间难度不同,我们对不同的子任务设置了不同的得分权重,来保证各个子任务之间的评估分量纲尽量一致。总分由四个场景累加计算且每个场景的权重一致。
Q3:初赛同一份权重评估为什么会有波动?在多大范围内算是合理的?评测子项具体代表什么?
A:目前使用的vllm框架推理,存在一定的波动,分数波动范围在1个百分位左右,评测结果栏表示的含义从左往右分别是总分、懂物料,懂用户(兴趣演化/选择),懂用户(兴趣演化/主题生成),懂推荐(短视频领域),懂推荐(电商领域),懂推荐(广告领域),懂推荐(直播领域),世界知识。
Q4:评测次数有限制吗,为什么评测任务完成了排行榜没有显示?
A:正式评测每天最多提交3次,每日 15:00(北京时间)刷新提交次数。所有提交必须在官方平台快手万擎上进行。排行榜每日 15:00(北京时间)更新;评估任务需在当日 12:00 点结束。
Q5:本地训练完后如何提交评测任务?
A:选手在本地训练完模型后,需要在【模型服务】-【模型托管】-【模型仓库】-【上传模型】选项下,上传模型参数,仅需上传模型参数即可,其他依赖文件将基于OneReason-0.8B-pretrain-competition自动填充。上传模型后,选手即可在【模型服务】-【模型评测】-【竞赛评测】-【新建评测任务】选项下,选择上传的模型,提交评测任务。具体操作指引可参考本文 4.2 路径二:自主训练模型 部分。
算力资源
Q1:比赛会提供训练资源吗?
A:初赛提供限量训练资源,初赛推理和复赛训推会全保障,暂不提供额外数据构造资源。目前由于赛题类型需求资源较大以及平台资源紧张无法满足初赛所有队伍的资源需求,需要队伍结合平台发布的算力资源和本地算力资源对模型进行调优,我们会在复赛阶段为每个复赛队伍提供训练资源,同时本次比赛也不提供免费API给选手用于数据构建。
Q2:官方算力具体怎么提供?
A:各阶段官方算力提供方式如下:
- 初赛训练:有算力支持,需注册万擎平台,比赛开始后每周会定时发放限量的资源代金券。第一周覆盖500支队伍,后续每周可训练的 Token 量级会进行公告。超出免费额度时需充值自费。
- 初赛推理:初赛推理资源平台将统一提供。
- 复赛训推:复赛所有队伍的训推全流程资源由平台统一提供。
- 使用方式:抢到名额的团队可以直接在万擎平台上使用模型微调能力进行训练,产出的 Checkpoint 就在平台上,不需要再次上传。只有使用自己算力资源训练的同学才需要上传 ckp。
Q3:模型精调的任务排队要多久?
A:赛事提供的免费资源是按照周级总算力估算的,当前作业提交比较密集,超过 100 支队伍并发提交作业,底层资源已经打满,正在有序排队消化中,预计 3-6h,最长不超过 12h。
Q4:自定义任务显示没资源,是否要申请?
A:初赛阶段万擎平台仅支持通过模型微调完成训练,复赛阶段会开放开发机,整个比赛期间均不支持免费使用自定义任务。
计量计费
Q1:使用代金券/折扣券有时间限制吗?
A:请在卡券有效期内完成训练任务,卡券会在任务成功后触发扣减,任务处理有耗时,建议选手在优惠券有效期前24h提交任务。
Q2:代金券余额如何查看?为什么提交任务之后没有费用记录?
A:任务成功后才会统计到准确的用量,再延迟一会出账去触发代金券抵扣,费用记录大概会延迟2h展示。
更多问题可见竞赛 FAQ 文档,如在平台使用过程中遇到问题,可通过比赛官方社群获取技术支持。
如在平台使用过程中遇到问题,可通过比赛官方社群获取技术支持。

